Creating a citation friendly bibliography database
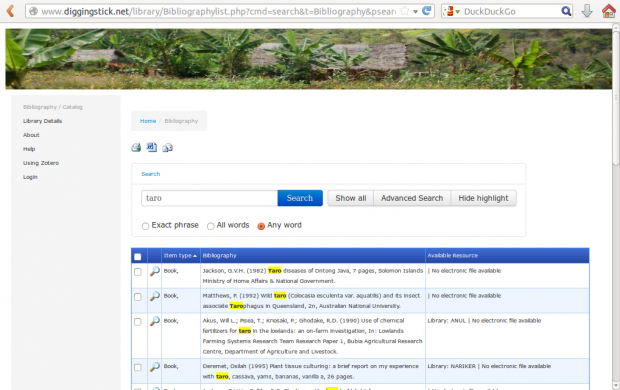
I had been reluctant to build a system from scratch, as even though it would give the flexibility we needed, the need to build in metadata harvesting by Zotero was a whole new learning curve! Take a look at the end product - a fully functional copy of the system (without the full text attachments) is available here on Digging Stick.
The database was built on PHP / MySQL, using PHPMaker. PHPMaker is an excellent productivity tool, providing heaps of bells and whistles, and looking after the coding while we concentrate on system design. The nature of the program ensures an understandable core codebase which can be picked up by another developer.
The design was constrained by the existing dataset of 39,000 records and need to bring across all existing fields. The old system was only able to export its data as a delimited text file. The most efficient way to clean the existing dataset and prepare it for import into the new system was to manipulate the data in a spreadsheet. This need for a simple spreadsheet based import system, was a key constraint to design, necessitating a single main reference table design, rather than 'normalised' tables. Its fine as it is, but can be adapted to a 'normalised' design once the need for backward compatibility with the old system has passed.
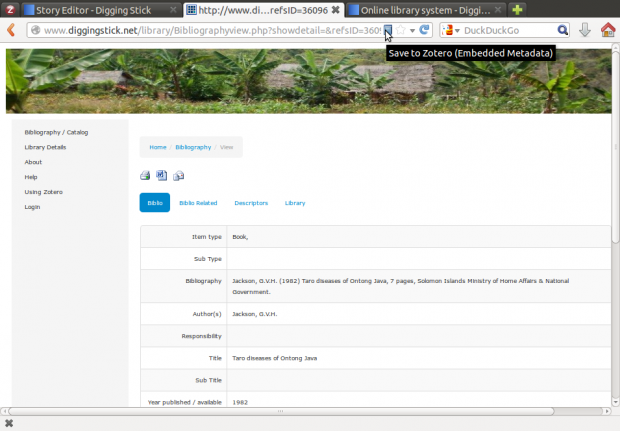
The interesting part was making the database 'Zotero friendly'. The Zotero documentation lists several ways to expose the site metadata (also see info on Zotero translators).
I implemented 'embedded metadata' in this system, using the <META> tags in the header of the record detail pages. The <META> tags in the header are then parsed and used by Zotero. As noted in the Zotero documentation,
"This fairly standard embedding of RDF metadata can use any RDF vocabularies; Zotero supports most major RDF vocabularies used for bibliographic metadata. For details on this approach, see the Dublin Core description. The translator will also interpret metadata expressed in the Google/Highwire key-value system." In developing this system, I used a combination of Dublin Core, Google Highwire, and Prism RDF vocabularies.
Where to next?
- Migrate to the free and open source PostgreSQL to take advantage of its 'Full Text Search' capabilities.
- Normalise the database framework
- Develop a site specific Zotero translator
- Develop a ZoteroRDF import/export capability to give another pathway for export of large numbers of records into Zotero and to import harvested records from Zotero - this will allow the librarians to take advantage of Zotero's ability to harvest metadata using the ISBN.
Tag: library repository metadata citation zotero postgresql phpmaker
What's Related